In this note, I use iris dataset from Kaggle to learn how to use TensorFlow Estimators to construct a DNN model.
Estimator Steps
- Read in data (+ normalize)
- Train/test split
- Create feature columns
- Create estimator input function and estimator model
- Train estimator model
- Predict with test input function
- Evaluation
Read in Data
import pandas as pd |
df = pd.read_csv('iris.csv') |
df.head() |
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0.0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0.0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0.0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0.0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0.0 |
To use TensorFlow estimator, there are some rules:
- the dataset’s column name can NOT include special characters (ex. ‘(‘ )
- the target should be integer.
Change the column name:
df.columns = ['sepal_length','sepal_width','petal_length','petal_width','target'] |
Spilt dataset into X and y, where y applied int casting:
X = df.drop('target',axis=1) |
Train Test Split
from sklearn.model_selection import train_test_split |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) |
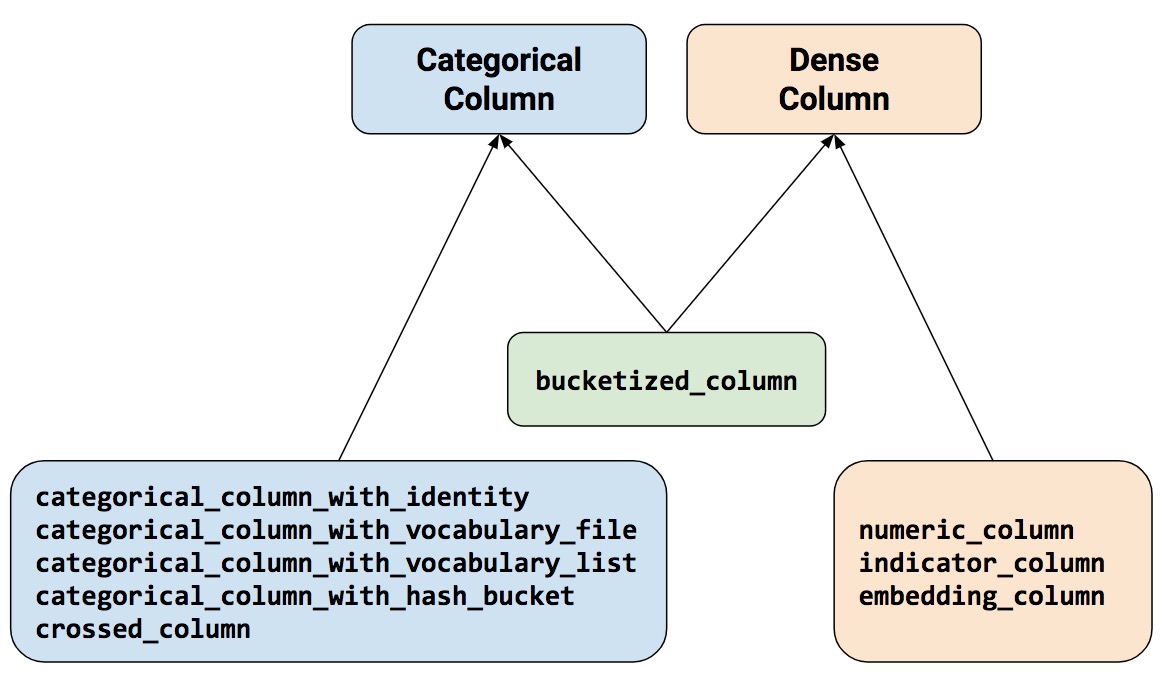
Create Feature Columns
Reference: Feature Columns
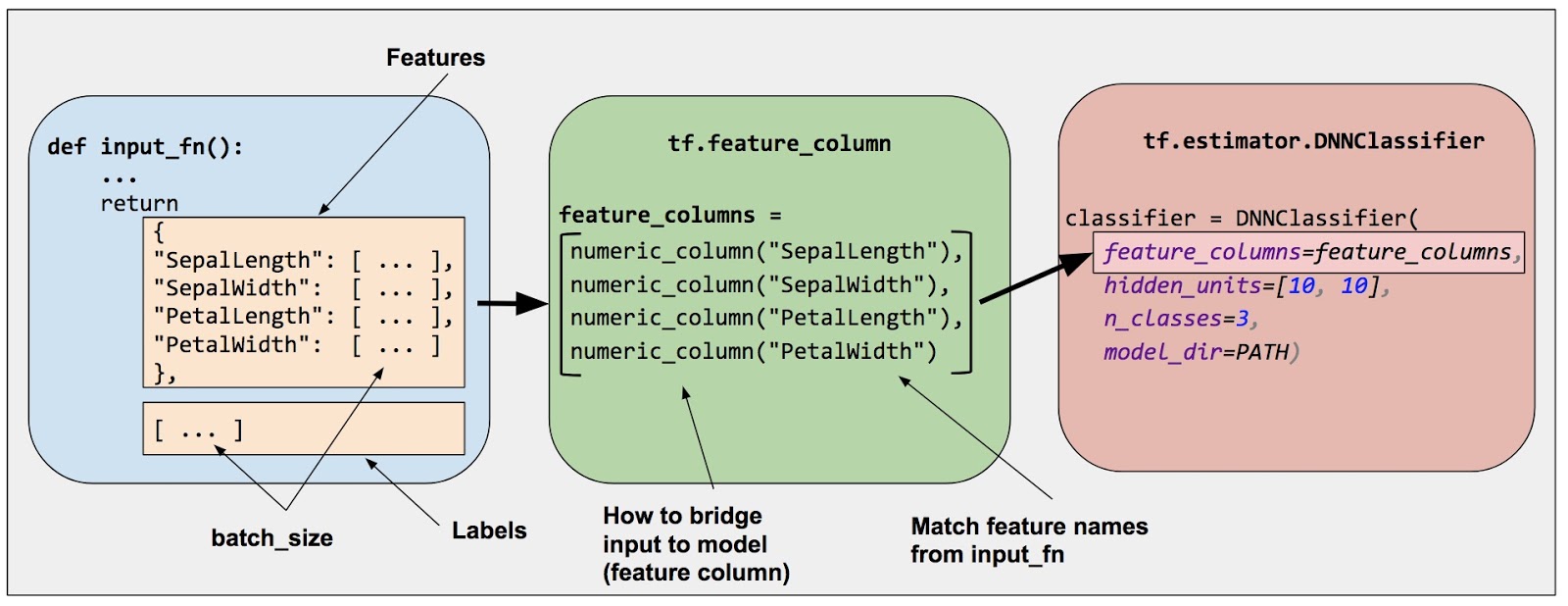
import tensorflow as tf |
X.columns |
Index(['sepal_length', 'sepal_width', 'petal_length', 'petal_width'], dtype='object')Transfer X columns from Pandas Series to TensorFlow Feature Columns(Numerical):
feat_cols = [] |
type(X['sepal_length']) |
pandas.core.series.Seriesfeat_cols |
[NumericColumn(key='sepal_length', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None),
NumericColumn(key='sepal_width', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None),
NumericColumn(key='petal_length', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None),
NumericColumn(key='petal_width', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)]Create Estimator Input Function and Estimator Model
Create Estimator Input Function:
# there is also a pandas_input_fn we'll see in the exercise!! |
Create DNN Classifier
To create DNN classifier, we need to know how many classes there are for the iris:
set(y) |
{0, 1, 2}It means we have 3 species: {0, 1, 2}
# hidden_units: list of number of neurons in each layer. len(hidden_units) = number of hidden layers |
Train Estimator Model
classifier.train(input_fn=input_func,steps=50) |
<tensorflow_estimator.python.estimator.canned.dnn.DNNClassifier at 0x1a57283c320>Prediction with Test Input Function
** Use the predict method from the classifier model to create predictions from X_test **
Create the input function for prediction:
pred_input_fn = tf.estimator.inputs.pandas_input_fn(x=X_test,batch_size=len(X_test),shuffle=False) |
Use classifier to predict pred_input_fn:
predictions = list(classifier.predict(input_fn=pred_input_fn)) |
predictions[0] |
{'logits': array([-2.4918616, 1.0184311, 0.2909072], dtype=float32),
'probabilities': array([0.01975435, 0.6609421 , 0.3193036 ], dtype=float32),
'class_ids': array([1], dtype=int64),
'classes': array([b'1'], dtype=object),
'all_class_ids': array([0, 1, 2]),
'all_classes': array([b'0', b'1', b'2'], dtype=object)}y_pred = [] |
Evaluation
Here we use Classfication Report and Confusion Matrix for Evaluation:
from sklearn.metrics import classification_report,confusion_matrix |
print(confusion_matrix(y_test,y_pred)) |
[[16 0 0]
[ 0 14 2]
[ 0 0 13]]print(classification_report(y_test,y_pred)) |
precision recall f1-score support
0 1.00 1.00 1.00 16
1 1.00 0.88 0.93 16
2 0.87 1.00 0.93 13
accuracy 0.96 45
macro avg 0.96 0.96 0.95 45
weighted avg 0.96 0.96 0.96 45Reference
Python for Data Science and Machine Learning Bootcamp
Feature Columns - TensorFlow Core